When you visit a website, everything you see on your screen is created using HTML, or HyperText Markup Language. This is basically the foundation of every webpage you see on the internet. If you’re interested in collecting data from websites, testing, or just trying to understand how webpages are structured and work, you might want to save a copy of a website’s HTML. This guide will show you how to download the HTML of a website, but please make sure you respect the website owners and follow the law before doing so.
Also see: Download All Files From a Website Directory Using Wget in Windows 11 or 10
First up, remember to play nice and check the website’s rules and the law before you go downloading anything. Look for a file called robots.txt on the site, and make sure what you’re doing is okay.
Page Contents
What is HTML?
HTML is the backbone that makes websites possible. It’s a computing language that web browsers use to display webpages graphically on your screen. In many websites, HTML also works with other technologies like CSS (which makes pages pretty and colorful) and JavaScript (which allows pages to do complicated stuff).
An HTML document is just a text file with HTML code, marked by tags that tell the browser how to show different parts of the page, like “heading,” “paragraph,” “table,” and so on.
Related resource: How to Convert HTML to PDF in Windows 11/10
How to download HTML file from a website
There are a few ways to download the HTML source code from a website, depending on what you need. We’ll go over some common methods like using a web browser, command line, and even Python.
Using a Web Browser
We’ll focus on Google Chrome here, but other browsers work similarly.
Downloading HTML source code from a website
- Open Google Chrome and go to the webpage you want.
- Right-click on the page and select “View Page Source” to see the HTML in a new tab.
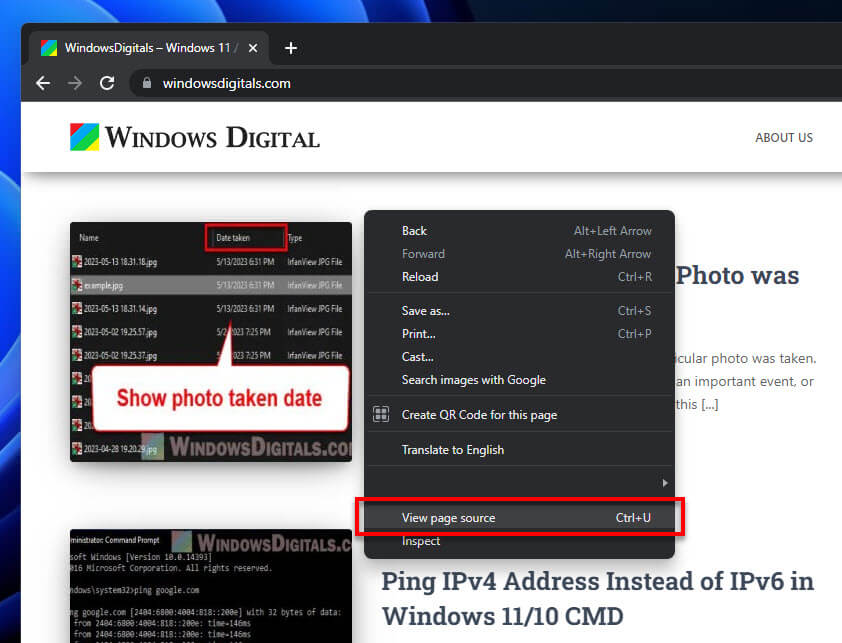
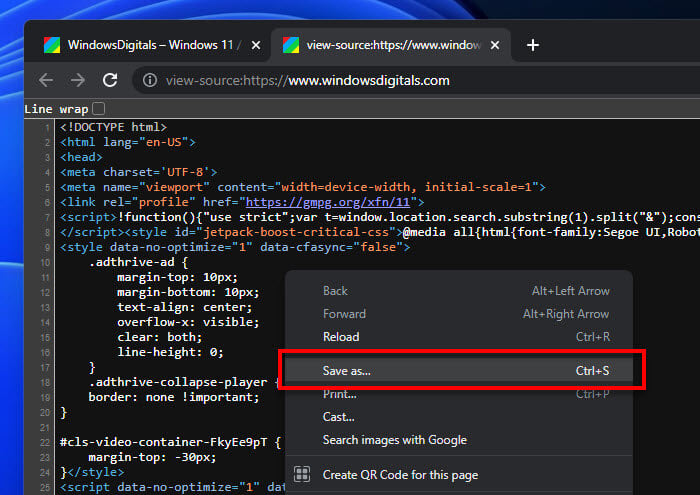
- Right-click in the new tab and choose “Save As” to save the HTML file on your computer.
Useful tip: How to Run HTML Code in Notepad Windows 11
Downloading HTML with pictures, CSS, and JS from a website
If you’re looking to grab an entire webpage with all its bells and whistles like pictures, CSS, and JS files, along with its HTML source code, here’s how you can do it:
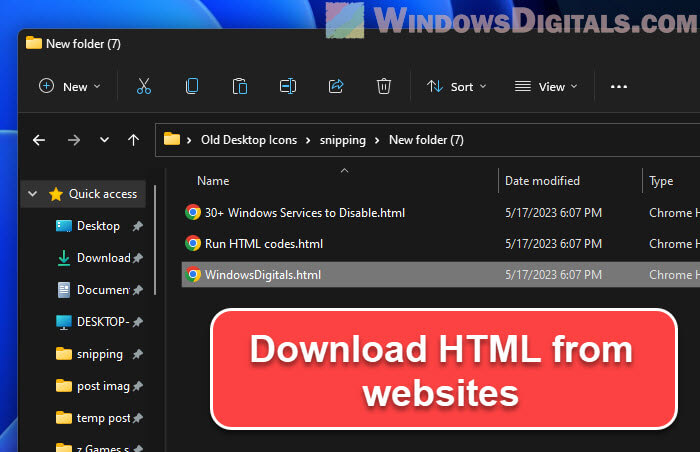
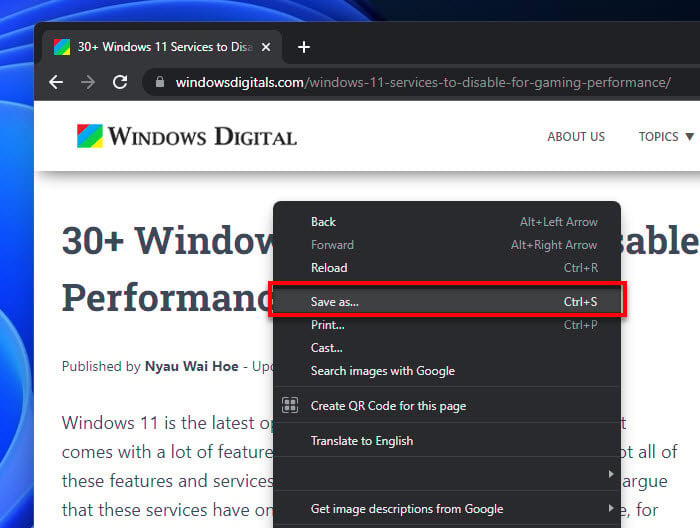
- First up, open Google Chrome and head to the webpage you want to download. Once you’re there, just right-click anywhere on the page and select “Save As”.
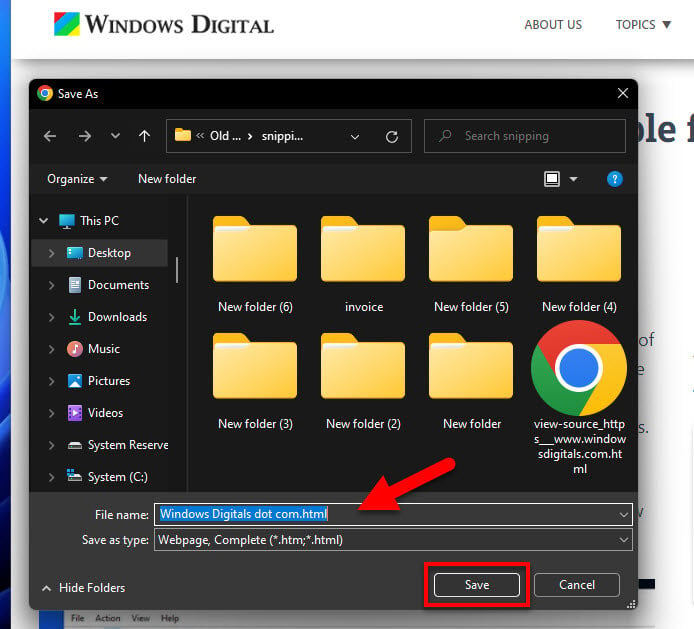
- Next, a box will pop up asking where you’d like to save the HTML file on your computer. Hit “Save”, and just like that, you’ve got the webpage’s HTML saved on your device.
When you save a webpage like this, whether it’s with Chrome or another browser, you’ll get two things:
- An HTML file: This is the .html file with the webpage’s HTML, which includes the structure and the content. It points to any external stuff the webpage uses, like images, CSS, and JavaScript files.
- A resources folder: Along with the HTML file, you’ll get a folder named just like the HTML file but with ‘_files’ at the end. This folder will have all the webpage’s resources that are now saved locally. This includes images, CSS files, JavaScript files, and more, which are needed for the webpage to look properly offline.
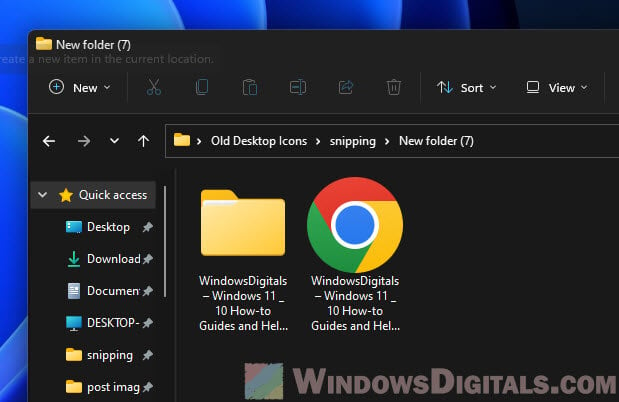
Note that the browser will change some of the HTML file’s links to these resources so they point to the local copies in the resources folder (e.g., instead of pointing to example.com/picture.jpg, it might be changed so that it points to C:\desktop\website\picture.jpg). This lets the webpage load up just fine even when you’re offline.
However, please know that not everything you download that way will work offline. For example, server-side scripts (like PHP) won’t run, and if the webpage gets resources on the fly with JavaScript, those will not be downloaded either.
Recommended guide: How to Check When a Web Page Was Last Updated
Why doesn’t Chrome save the HTML as a single file?
The main reason is all about keeping the webpage working and looking as it should. Webpages are complex, with not just HTML but also CSS for the looks and JavaScript for the action. These bits are usually in separate files. If Chrome crammed everything into one HTML file, it would have to stuff all these resources directly into the HTML, which can mess with how easy it is to read, edit, and how well it runs.
So, to keep everything running smoothly and looking good, Chrome saves the HTML and its resources as separate files, rather than mixing it all into one file.
See also: Create Website or Application Shortcut on Desktop using Chrome
Using the command line
If you’re on Linux or MacOS, you can use commands like wget or curl to download a website’s HTML.
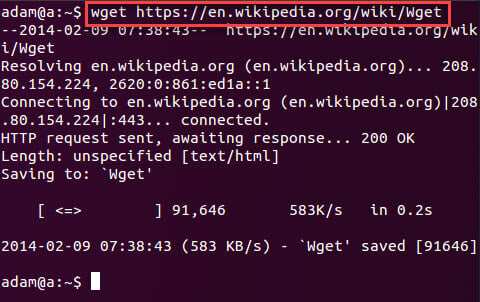
- Using wget:
wget https://example.com
This saves the webpage’s HTML in your current folder.
- Using curl:
curl https://example.com > example.html
This saves the webpage’s HTML into a file named “example.html”.
Using Python
Python is also extremely good for downloading HTML of webpages. The following is a quick script to do so:
import requests
url = "https://example.com"
response = requests.get(url)
with open('example.html', 'w') as file:
file.write(response.text)
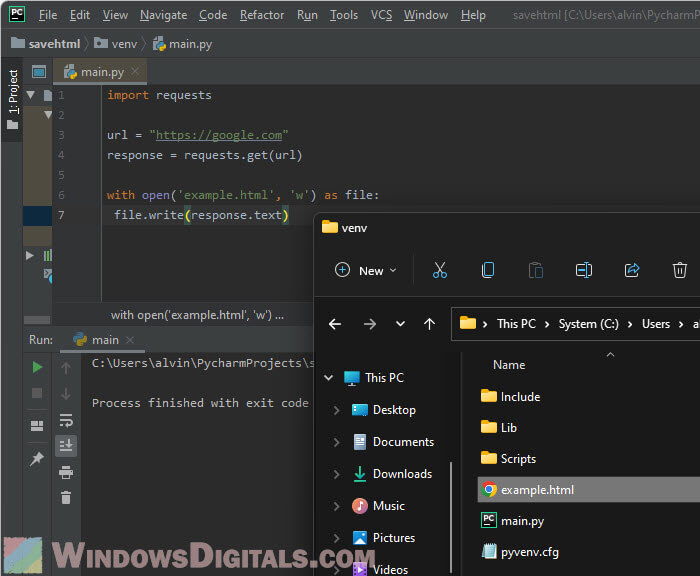
This Python script will request a website for its HTML and then saves it to a file called “example.html” on your computer. If you’re new to Python and encounter any error that say it can’t find a module, you will need to install the module using Python’s package manager (pip). Just open your command line and type:
pip install requests
This will install the needed module. If you need another module, you can install it using the same way.
Advanced usage – Web scraping
Once you’ve got the HTML, you might also want to pull out only specific parts of the webpage. This is where web scraping comes in handy. Python has a library called beautifulsoup4 that’s perfect for this. It lets you sift through HTML very easily.
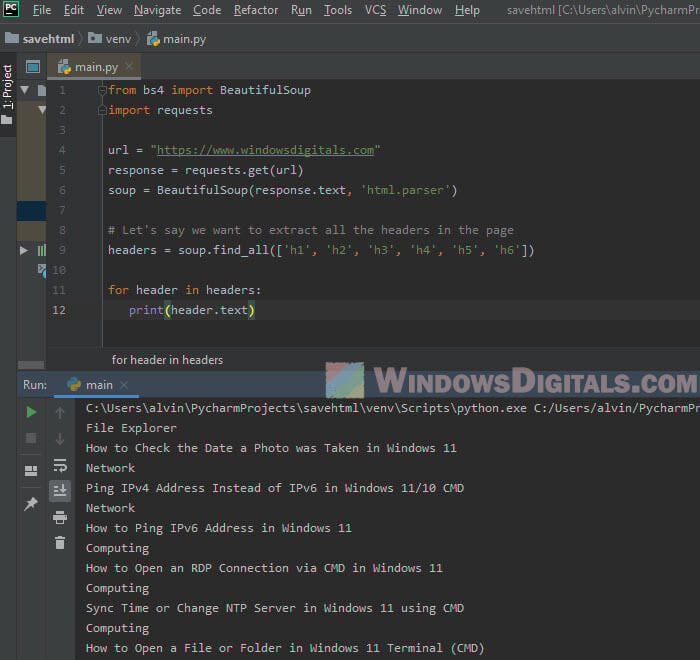
The following is a quick example:
from bs4 import BeautifulSoup import requests url = "https://example.com" response = requests.get(url) soup = BeautifulSoup(response.text, 'html.parser') # Let's say we want to extract all the headers in the page headers = soup.find_all(['h1', 'h2', 'h3', 'h4', 'h5', 'h6']) for header in headers: print(header.text)
In this script, BeautifulSoup is used to parse the HTML. The find_all function is then used to find all header tags in the HTML. The script then prints the text of each header tag.
Dealing with dynamic content
Some websites load their content on the fly, meaning you might not get everything by just saving the HTML. For these cases, you can use tools like Selenium, Puppeteer, or Playwright. These tools actually open up a web browser, let the page load completely, and then let you access the HTML.
Here’s how you can use Selenium with Python:
from selenium import webdriver
# Make sure the chromedriver is in your PATH
driver = webdriver.Chrome()
driver.get('https://example.com')
html = driver.page_source
with open('example.html', 'w') as file:
file.write(html)
driver.quit()
This method can be a bit slow and uses more resources, but it’s good for getting everything from pages that load content dynamically.
One last thing
Whether you’re into coding, testing, or just curious about how websites work, knowing how to download HTML is a very useful skill. There are lots of ways to do it, depending on what you need and what tools you’ve got. Just make sure to always respect the website’s rules and only download stuff when it’s okay to do so.